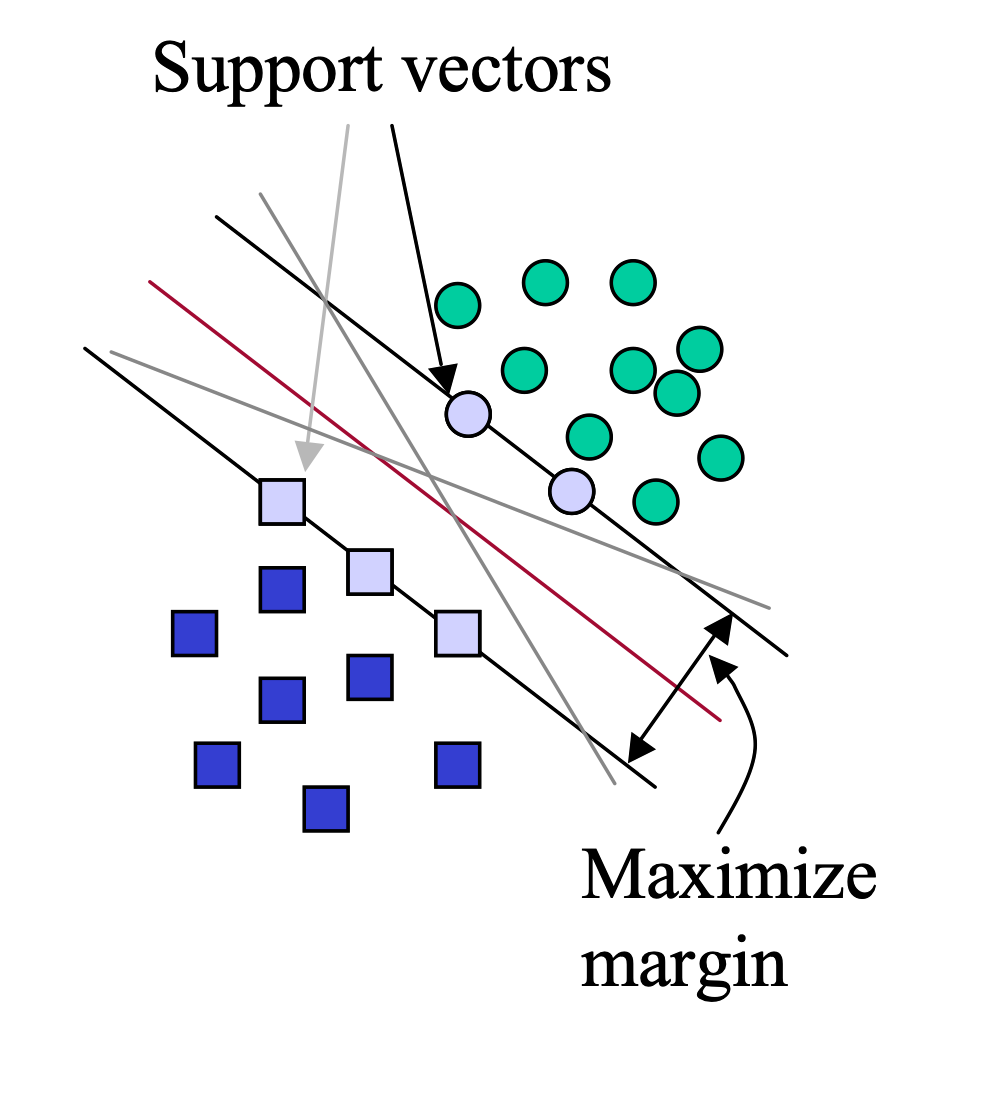
(also known as SVM) a supervised machine learning algorithm used for classification and regression tasks. It is a margin-maximising linear classifier. It tries to find the best boundary that separates different classes in the data.
Principle
In the study design, hyperplanes (the decision boundaries separating classes) are only one or two-dimensional. This means that the hyperplanes can only be 1D lines or 2D planes.
The margin is defined as a distance from the hyperplane to the nearest data points. The nearest data points to the line are called the support vectors.
The main goal of the algorithm is to maximise the margin between the two classes. The larger the margin, the better the model performs on new and unseen data. 1
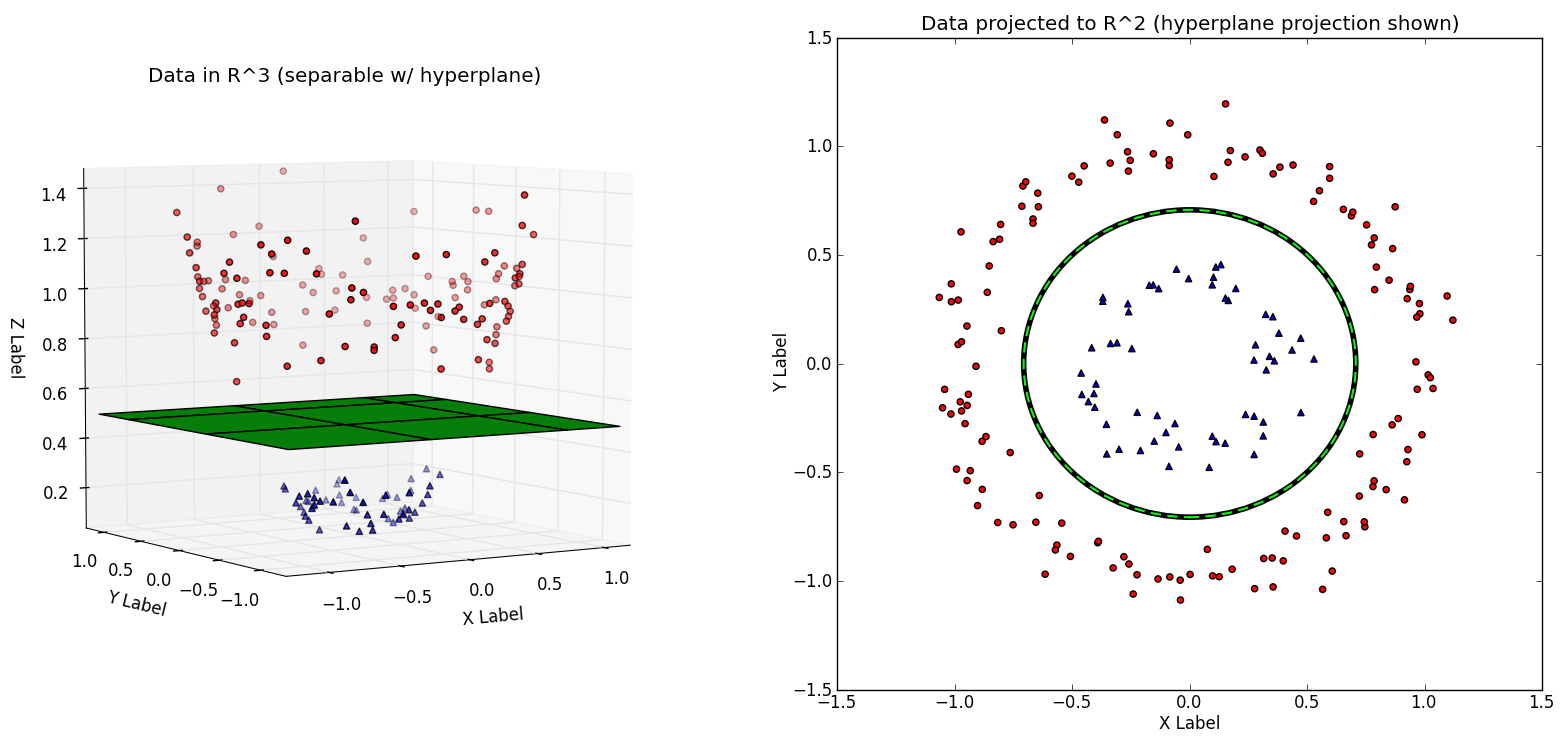
Creating a second feature from one-dimensional data
One-dimensional data may not be separable with a simple point. For example, data may be arranged like: A, B, A, B, A, B. This is called non-linear separability.
To solve this, we transform the data by introducing a new feature () from the second one. A common way is by applying a non-linear function to the original feature (), such as .
This moves the data from a one-dimensional line to a two-dimensional plane. The new space may now contain a linearly separable pattern by plotting the points , and a straight line can be drawn to seperate the two classes.